Preserve or Modify? Context-Aware Evaluation for Balancing Preservation and Modification in Text-Guided Image Editing
| Yoonjeon Kim* | Soohyun Ryu* | Yeonsung Jung | Hyunkoo Lee |
| Joowon Kim | Juneyong Yang | Jaeryong Hwang | Eunho Yang |
| *Equal contribution. |
arXiv | AugCLIP
Abstract
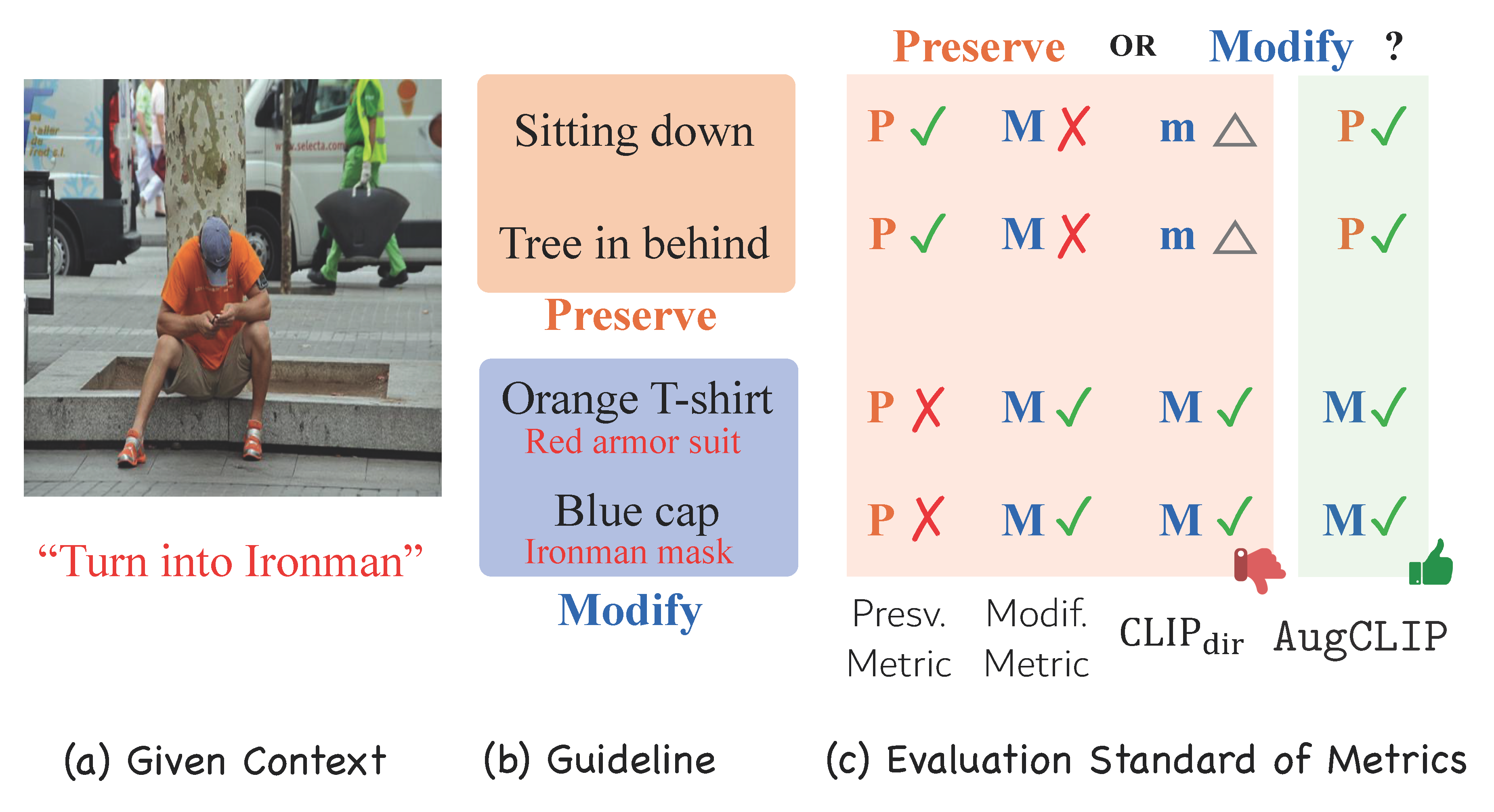
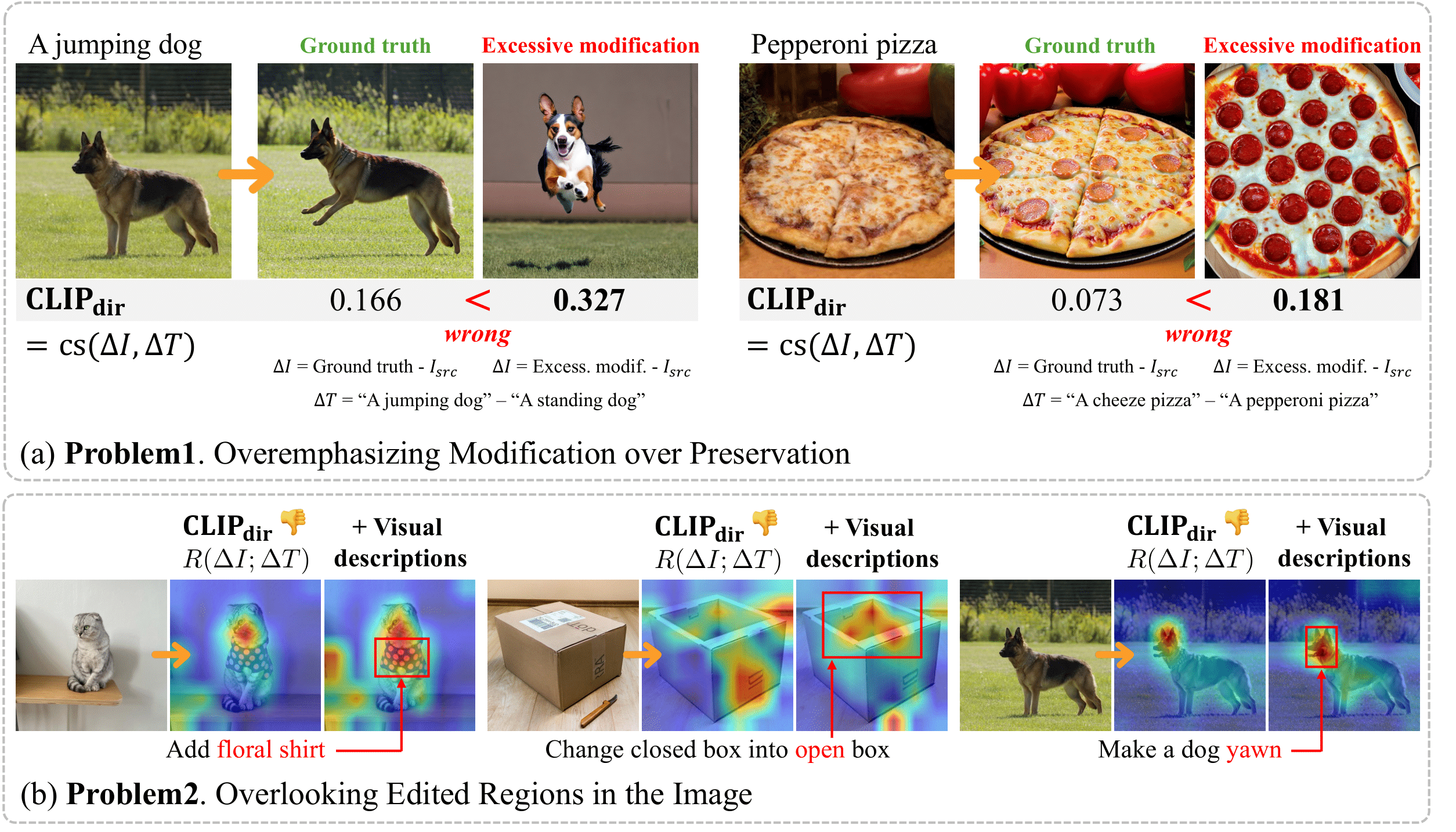
The development of vision-language and generative models has significantly advanced text-guided image editing, which seeks the preservation of core elements in the source image while implementing modifications based on the target text. However, existing metrics have a context-blindness problem, indiscriminately applying the same evaluation criteria on completely different pairs of source image and target text, biasing towards either modification or preservation. Directional CLIP similarity, the only metric that considers both source image and target text, is also biased towards modification aspects and attends to irrelevant editing regions of the image. We propose AugCLIP, a context-aware metric that adaptively coordinates preservation and modification aspects, depending on the specific context of a given source image and target text. This is done by deriving the CLIP representation of an ideally edited image, that preserves the source image with necessary modifications to align with target text. More specifically, using a multi-modal large language model, AugCLIP augments the textual descriptions of the source and target, then calculates a modification vector through a hyperplane that separates source and target attributes in CLIP space. Extensive experiments on five benchmark datasets, encompassing a diverse range of editing scenarios, show that AugCLIP aligns remarkably well with human evaluation standards, outperforming existing metrics.
Problems of Directional CLIP Similarity
Method
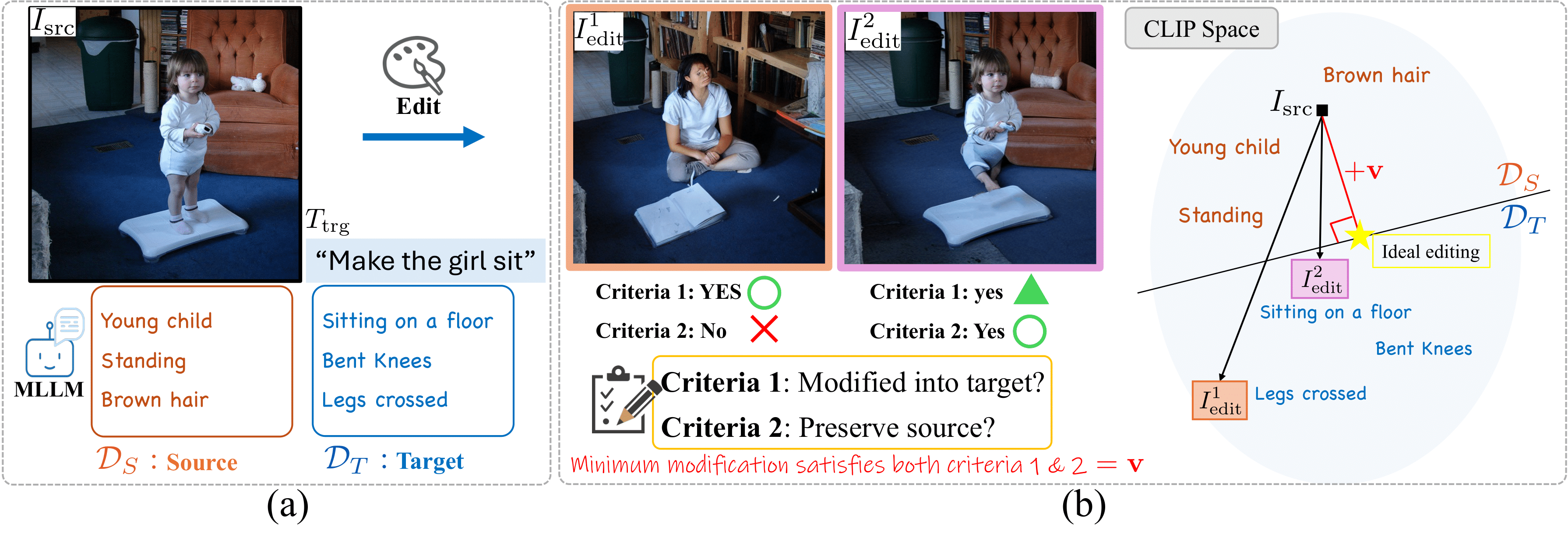
Given a target text \(T_\text{trg}\) and a source image \(I_\text{src}\), AugCLIP measures the cosine similarity between the edited image \(I_\text{edit}\) and the ideal editing. Since the ideal edited image is not given in most evaluation cases, we estimate the representation of an ideally edited image as a modification on the source image, \(I_\text{src} + \mathbf v\), where \(\mathbf v\) is the modification vector.





Paper
|
"Preserve or Modify? Context-Aware Evaluation for Balancing Preservation and Modification in Text-Guided Image Editing", Yoonjeon Kim*, Soohyun Ryu*, Yeonsung Jung, Hyunkoo Lee, Joowon Kim, Juneyong Yang, Jaeryong Hwang, and Eunho Yang. Conference on Computer Vision and Pattern Recognition (CVPR) 2025 [PDF] |